

The brachial plexus is a network of nerves in the shoulder that relays signals from the spinal cord to the arm. The inferior trunk of the brachial plexus is anaesthetized before surgeries that involve the shoulder and arm in a technique known as a supraclavicular block. Locating the brachial plexus is vital to the success of the procedure, as its position near an artery and the pleura (the membrane surrounding the lungs) demands intricate anatomical knowledge.
To locate the brachial plexus, an ultrasound is used. Ultrasound specialists and anaesthetists identify landmarks in the image, such as the first rib, the subclavian artery, and the pleura to locate the inferior trunk. The needle should never enter what is called a “no-fly zone” below the first rib, where thoracic security would be put in jeopardy. When we humans look at an ultrasound and look for landmarks, we look for large structures in the image: a thick white line for a rib, a pulsating circle for an artery, etc.
If we want to automate this process of recognizing the brachial plexus in an image, we need to consider several constraints. First, common ultrasounds are greyscale images, so we lose any color information. Second, we are analyzing static images, so we do not have the hands-on maneuverability nor the ability to see the subclavian artery pulsating. Finally, the intuitive way that we find large structures in an image cannot be directly translated into a computer program.
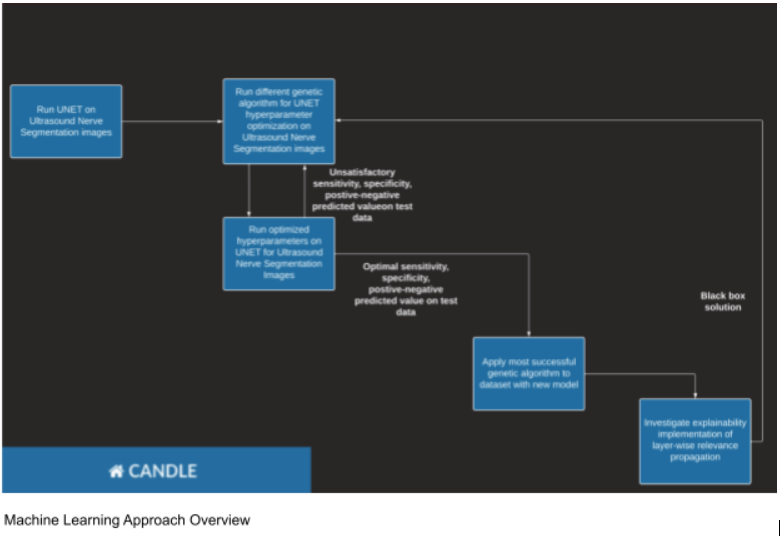
A common approach to allow a computer to recognize structures in an image is to use machine learning, specifically a neural network. A neural network learns based on a set of distinct input and output data. In this case, the dataset comprises images of greyscale ultrasounds and their corresponding “masks”. Masks are pure black-and-white images highlighting the location of the brachial plexus. To learn from the data, the network feeds forward an ultrasound, obtains a predicted mask, and compares it to the correct answer. It then updates its parameters based on the differences between the prediction and answer using a user-defined loss function. After thousands of iterations, the model learns to distinguish between which pixels are part of the plexus and which are not. Once the model is trained, new ultrasound images can be submitted to generate a new prediction. However, by only seeing the input and output of the model, we do not have an explanation for the model’s prediction, i.e. why did the model decide that certain pixels were (not) part of the mask? To get insight into the black box of the network we turn to explainable artificial intelligence methods (XAI) that shed light on the inner workings of a model. This would be helpful while debugging the model or attempting to rework the model—furthermore, it increases user trust and confidence in what often seems like an arbitrary prediction. In addition, the user defines the model with certain hyperparameters, such as the number of iterations (hundreds, thousands, millions?) and the number of images passed through the model at once. Note that these vary based on the exact type of machine learning implementation. Hyperparameter tuning can be accomplished through optimization algorithms, which are subtle ways to improve a model’s efficiency and accuracy. In summary, the three components of a robust approach are rigorous training, understandable predictions, and optimized hyperparameters.
Training a model to recognize images can be accomplished using a convolutional neural network (CNN). The basic unit of a CNN is the convolutional layer. A convolutional layer has an image as both its input and output, as opposed to a standard neural network that uses one-dimensional vectors. The convolutional layer applies a filter or kernel to the image, where the filter itself is a small matrix (often a 3x3 square) that represents an intricate detail in the image. Through the convolution operation, parts of the image that match the filter are emphasized, whereas parts that do not are dimmed. When several filters are applied in parallel, we obtain not just one but a multitude of these so-called feature maps. Now, a second convolutional layer can be used to analyze each of those feature maps, possibly with a menagerie of filters as well. The second layer, however, is no longer dealing with the same scale of features as the first layer. The second layer, rather than working with individual pixels, considers arrangements of features—from the first layer’s feature maps. When several layers are linked in a CNN, the model can eventually distinguish the large structures that we humans find so easily.
The U-Net architecture is a specific framework for organizing convolutional layers in two sections: an encoder and decoder. As you may have guessed, the encoder, through several convolutions, condenses information from the original image into small packets of data. The decoder then expands those packets into a purely black-and-white (as opposed to greyscale) image. The black shows the parts of the image that the model predicts do not contain the brachial plexus, while the white part (the mask) is the predicted area with the brachial plexus. The model learns, or is trained on, a dataset with ultrasounds and their corresponding masks. During the training process, the model converts an ultrasound to a mask, compares it to the correct mask using a loss function, and updates the values in the filter matrices accordingly. Thus, after thousands of iterations, the model is adequate at recognizing where the nerve appears, and where the nerve does not.
-----
Once we have our trained model, we can use it to generate new mask predictions based on ultrasounds the model has never seen before. Yet, we will not be able to justify the model’s predictions beyond verifying its accuracy. We cannot trust that the model is making decisions with valid logic, e.g. recognizing a rib and then marking the area next to it as a possible mask. Models with unexplainable logic are known as “black boxes” for their opacity. One class of XAI, propagation, focuses on finding the exact parts of the input that led to the model’s prediction. It specifies a quantity relevance that encapsulates the prediction at each output pixel, and then through each layer divides that relevance into a distribution of relevances for the input images of that layer. After propagating through each layer and returning to the input, we can get a heat map that shows us which parts of the image were most important for the model’s prediction. This allows us to verify that the model is actually building the correct conclusions from stepwise convolutions—which appear quite esoteric at first.
-----
The last piece of the puzzle of our robust model is hyperparameter optimization. A hyperparameter is a parameter of a machine learning model that is used to control the learning process. An example of a hyperparameter is batch size. Previously, we simplified the training phase of a neural network. In reality, the network may feed forward more than one ultrasound at a time, and then aggregate their differences to tune the weights. That group of images is referred to as a batch. Changing batch size impacts the time it takes the model to train as well as the memory required to perform the necessary computations. Other hyperparameters are the number of epochs (how many passes the model makes through the data), kernel size, weight initialization, and learning rate. A genetic algorithm is a method for optimizing hyperparameters based on the principle of evolution through natural selection. We generate a population of possible hyperparameter values in a particular encoding scheme, and then introduce randomness and an evaluation metric to select more refined values after each generation. There are many ways this can be done, but one example is through mutations, where an “organism” is changed with some probability and then compared to the previous iteration. Replicating this process with hundreds of organisms selects for the hyperparameters that optimize our metric, which can be chosen based on the application (e.g. for tumor detection one might value sensitivity, whereas for our anaesthetic problem we would emphasize specificity).
-----
While a CNN provides a useful solution to our problem, it requires intensive computational resources. For this reason, it is incredibly beneficial to train deep neural networks (networks with several layers between the input and output) with High Performance Computing (HPC). Parallelization is an efficient way to make use of the resources HPC provides. Parallelization involves splitting one task into many mutually independent processes, whose results can be aggregated at the end. Parallel programs run much faster than their sequential counterparts. One operation that parallelization drastically accelerates is matrix multiplication. From our discussion on convolutional layers, the productivity boost is obvious. CANDLE is a framework for writing parallelizable code and executing it using HPC. It was originally developed as a collaboration between the United States Department of Energy (DOE) and the National Institutes of Health (NIH). The DOE used it to advance their understanding of HPC, while the NIH’s interest was in processing large volumes of cancer data. CANDLE is implemented using Swift/T, a language capable of determining a parallel schedule given a program.
-----
To evaluate the performance of our model, we make use of four statistical measurements: sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV). Briefly, sensitivity measures how well the model detects positives, specificity measures how well the model detects negatives, and the two predictive values give a confidence level for a positive and negative prediction. Depending on the exact application, we may prefer to maximize one metric over the other. For example, if we applied U-Net to a tumor detection problem, we could fear false negatives much more than false positives (i.e. we would aim to maximize the statistical power of our model). This might translate to valuing sensitivity during training or the hyperparameter optimization. Conversely, if we were testing for a rare disease where Bayes’ Theorem may lead to overwhelming false positive rates, we might emphasize predictive value and specificity.
In summary, the U-Net architecture is a powerful tool for image processing, all more so using High Performance Computing resources and the CANDLE framework. While here we focused on its application to ultrasound segmentation problems, the machine learning approach could be applied to a vast array of problems, further showing us the power and utility of artificial intelligence.
Add new comment